We build retrieval-augmented generation systems that ground AI responses in your actual documents. Not hallucinated facts—verified information with citations. From knowledge bases to customer support, we deliver RAG that works in production.
Risk-Free Start
Oleg Kalyta
Founder & AI Lead
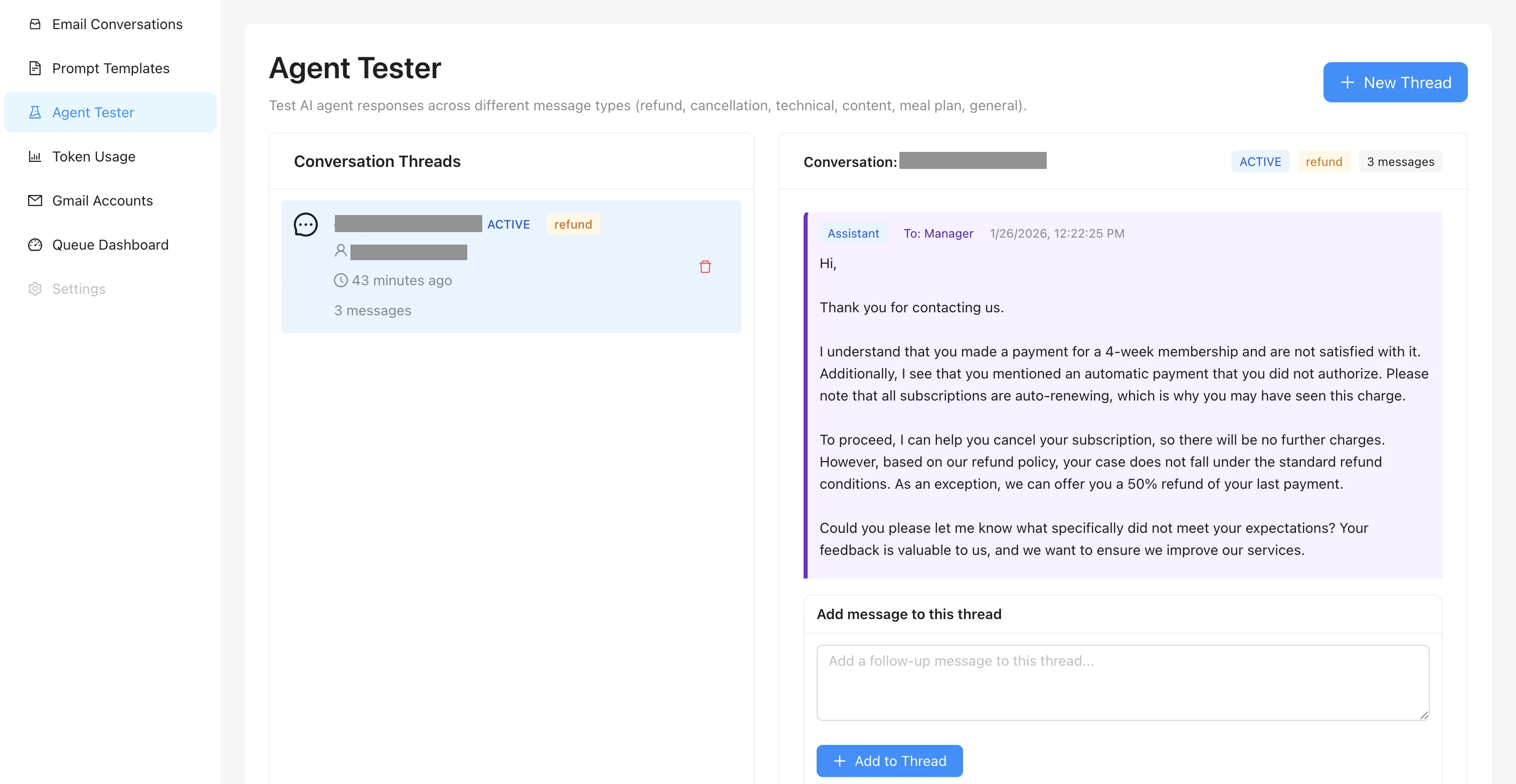
Your RAG Project Timeline
FREE
Week 1
Free Discovery
Document analysis, architecture recommendation
1
Week 2-6
RAG Prototype
Working system with your documents
2
Month 2-3
Production Ready
Full solution deployed
Projects featured in
RAG Development Challenges We Solve
These are the problems that bring companies to us. Sound familiar?
LLM responses are unreliable or hallucinate facts
RAG grounds every answer in retrieved documents. Citations let users verify. Confidence thresholds prevent overconfident wrong answers.
Knowledge is trapped in documents nobody can search effectively
RAG makes your documents searchable with natural language. Semantic search finds relevant content even when keywords don't match.
Keeping AI current requires expensive retraining
RAG retrieves from your live knowledge base. Update a document and the system knows immediately. No retraining required.
Generic chatbots don't know your product or policies
RAG connects LLMs to your actual documentation. Every answer specific to your business, not generic web knowledge.
Support costs are scaling faster than revenue
RAG-powered support agents handle routine queries autonomously. Our benchmark: $0.02 per conversation, 70% ticket automation.
Compliance requires traceability for AI-generated content
Every RAG response cites source documents. Full audit trails. Regulators can verify. No black box answers.
$0.02Per conversation
70%Tickets automated
5.0★Clutch rating
$2M+Raised by clients
RAG Development Services
From architecture through deployment and optimization. We handle the full RAG development lifecycle.
RAG Architecture & Strategy
Most RAG projects fail before they start. Wrong chunking strategy. Embedding model that doesn't fit your content type. Vector database chosen for the wrong reasons. We spend the first week understanding your documents, your queries, and your accuracy requirements. Then we design an architecture that actually works. Not a generic template—a system built for your specific knowledge base.
Custom RAG Application Development
End-to-end RAG systems that go beyond basic document Q&A. We build applications where retrieval is just the beginning—summarization, comparison, extraction, report generation. The interface your users interact with. The APIs your systems call. The monitoring that catches problems before users notice. Production-grade, not proof-of-concept-grade.
RAG Pipeline Engineering
The retrieval pipeline makes or breaks RAG quality. Chunking strategies that preserve context. Embedding models that understand your domain vocabulary. Reranking that surfaces the right documents. Hybrid search when semantic alone isn't enough. We tune each component until retrieval precision hits your accuracy targets. Most projects need 85%+. Some need 95%+. We get there.
Enterprise Knowledge Base Systems
Corporate knowledge trapped in SharePoint, Confluence, Google Drive, and dozens of other places. We build RAG systems that unify it. Employees ask questions in natural language and get answers with citations—from the actual source documents, not hallucinated facts. Role-based access ensures people only see what they're authorized to see. The enterprise search you always wanted.
RAG Chatbot Development
Chatbots that don't make things up. Every answer grounded in your documents. Every response includes sources. Conversation history that maintains context across turns. Graceful handling when the knowledge base doesn't have the answer. We integrate with Slack, Teams, your website, your mobile app—wherever your users are. Not a generic chatbot with your logo. A knowledge assistant that knows your business.
Agentic RAG Systems
RAG that reasons before it retrieves. Multi-step queries decomposed into sub-questions. Agents that decide which knowledge bases to search. Systems that synthesize information across sources, compare documents, and build structured outputs. This is where RAG meets AI agents—autonomous reasoning backed by your actual data. Still emerging. Complex to get right. Worth it when you need it.
RAG Projects We Have Delivered
Real projects, measurable results. RAG systems in production serving actual users.
Most clients start unsure whether they need RAG, fine-tuning, or something else entirely. That's what the discovery phase is for.
RAG Solutions We Build
Different problems require different RAG architectures. Here are the systems we develop.
Document Q&A Systems
The most common RAG use case. Upload documents, ask questions, get answers. But production-grade document Q&A is harder than it looks. Legal contracts with nested clauses. Technical manuals with tables and diagrams. Research papers with citations. We handle document complexity that breaks generic RAG solutions. Output includes source citations, confidence indicators, and graceful fallbacks when information isn't found.
Customer Support RAG
Support agents that actually know your product. Not because they memorized FAQs—because they retrieve from your entire knowledge base: product docs, past tickets, internal wikis, release notes. Customers get accurate answers in seconds. Support tickets that used to take hours get resolved in minutes. Our AI support agent runs at $0.02 per conversation. That's the benchmark we hit.
Internal Knowledge Assistants
Employees spend 20% of their time searching for information. Usually they give up and ask a colleague. Or worse—they guess. Internal knowledge assistants give instant access to company knowledge: policies, procedures, technical specs, project history. New employees get up to speed faster. Experts stop answering the same questions. Institutional knowledge stops walking out the door when people leave.
Research & Analysis Tools
Analysts drowning in documents. Market research reports, competitor filings, industry publications, internal memos. RAG systems that let them ask questions across the entire corpus. Compare positions across documents. Identify contradictions. Generate summaries with citations. We've built these for legal due diligence, competitive intelligence, and academic research. Turns weeks into hours.
Compliance & Policy Systems
Regulatory requirements scattered across hundreds of documents. Policy updates that employees miss. Compliance questions that require legal review. RAG systems that know your regulatory landscape. Employees ask 'Can we do X?' and get answers citing specific policy sections. Auditors ask questions and get documented evidence. Keeps you compliant without slowing you down.
Multi-Modal RAG
Text isn't everything. Technical diagrams that explain how systems work. Product images that show variations. PDFs with embedded charts. Video transcripts with timestamps. Multi-modal RAG retrieves across content types. Ask a question about a schematic and get the relevant diagram. Search for a product feature and see the actual interface. Still maturing. We know what works and what's still experimental.
What Founders Say
Transparent pricing based on project scope and complexity. Here's what typical ML initiatives cost based on projects we've delivered.
We met our deadlines and we are still in the budget that I think is very rare for tech products. Couldn't be happier.
Founder of Morsel
Ian Hoyt
They overachieved when it came to the production timeline on a couple of occasions, and the internal stakeholders are particularly impressed with their receptiveness and dedication.
Partner @ Glitch Creative Labs
Devon Smittkamp
They were diligent, fast, they delivered. They’ve been awesome, every step of the way.
Founder of Wavedash GmbH
Laurids Düllmann
ProductCrafters always found a way to implement what we wanted. Everyone there is impressively dedicated to delivering a perfect solution. Their dedication is unmatched.
RAG Technology Stack
We work with leading vector databases, embedding models, and frameworks. The right tools for your requirements.
Vector Databases
Pinecone
Weaviate
Chroma
PostgreSQL + pgvector
Pinecone
Weaviate
Chroma
PostgreSQL + pgvector
Pinecone
Weaviate
Chroma
PostgreSQL + pgvector
Pinecone
Weaviate
Chroma
PostgreSQL + pgvector
Pinecone
Weaviate
Chroma
PostgreSQL + pgvector
Pinecone
Weaviate
Chroma
PostgreSQL + pgvector
LLMs & Embeddings
OpenAI
Claude
Gemini
Hugging Face
OpenAI
Claude
Gemini
Hugging Face
OpenAI
Claude
Gemini
Hugging Face
OpenAI
Claude
Gemini
Hugging Face
OpenAI
Claude
Gemini
Hugging Face
OpenAI
Claude
Gemini
Hugging Face
Frameworks
LangChain
LangGraph
Python
FastAPI
LangChain
LangGraph
Python
FastAPI
LangChain
LangGraph
Python
FastAPI
LangChain
LangGraph
Python
FastAPI
LangChain
LangGraph
Python
FastAPI
LangChain
LangGraph
Python
FastAPI
Infrastructure
AWS
GCP
Docker
Kubernetes
AWS
GCP
Docker
Kubernetes
AWS
GCP
Docker
Kubernetes
AWS
GCP
Docker
Kubernetes
AWS
GCP
Docker
Kubernetes
AWS
GCP
Docker
Kubernetes
RAG Development Process
Industries We Serve
RAG applications vary dramatically by industry. Domain knowledge matters as much as technical skill.
Healthcare & Life Sciences
Clinical knowledge retrieval for physicians. Patient education systems that cite medical sources. Drug information databases with interaction checking. Research literature assistants for life sciences teams. Healthcare RAG requires HIPAA compliance, medical terminology understanding, and extreme caution about the consequences of wrong answers. We've built AI systems that process thousands of patient interactions daily—with appropriate guardrails and human oversight. The stakes are too high for generic solutions.
Financial Services
Regulatory document analysis. Compliance knowledge retrieval. Investment research across thousands of filings. Customer service automation for banking products. Financial RAG needs audit trails, explainability for regulators, and careful handling of advice boundaries. We build systems where every answer traces back to source documents. Compliance teams can review. Auditors can verify. No black boxes allowed.
Legal
Contract analysis at scale. Legal research across case law and statutes. Due diligence automation. Policy compliance checking. Legal RAG demands precision—missing a clause or misinterpreting precedent has consequences. We fine-tune retrieval for legal language, implement citation verification, and build confidence thresholds that prevent overconfident wrong answers. Lawyers review the edge cases. The system handles the volume.
Technology & SaaS
Technical documentation search that actually works. Developer support chatbots. Internal knowledge bases for engineering teams. Customer support automation for complex products. Tech companies often have the sophistication to implement RAG but lack the specialized ML engineering bandwidth. We bridge that gap—turning scattered documentation into searchable, conversational knowledge. Our AI support agent reduced response times from 4 hours to under 1 minute.
Manufacturing & Industrial
Technical manuals for equipment maintenance. Safety procedure retrieval. Quality control documentation. Supply chain knowledge bases. Manufacturing RAG handles specialized terminology, equipment specifications, and safety-critical information. Field technicians get answers without calling headquarters. Quality teams access the right specs instantly. We build for environments where downtime costs money and safety isn't optional.
E-commerce & Retail
Product information retrieval across thousands of SKUs. Customer service automation that knows your catalog. Comparison tools that help customers decide. Internal knowledge bases for retail staff. E-commerce RAG handles constantly changing inventory, seasonal variations, and customer questions that span products. Accurate product information increases conversion. Automated support scales with traffic spikes.
RAG Development Investment
Honest pricing based on real projects. No competitor shows RAG development costs. We do.
RAG Prototype
Validating RAG viability before full investment
$15,000 – $25,000
4-6 weeks
Document analysis and chunking
Vector database setup
Basic retrieval pipeline
Simple chat interface
Accuracy evaluation
Feasibility report
Proof of concept with your actual data. Single document source. Basic retrieval pipeline. Working interface to test with real queries. Validates the approach before larger investment.
Production RAG System
Production deployment for internal or customer-facing use
$35,000 – $75,000
8-12 weeks
Multi-source document ingestion
Advanced chunking strategies
Hybrid search (semantic + keyword)
Reranking for precision
Full application development
Integration with existing systems
Monitoring and analytics
90-day support included
Complete RAG application ready for real users. Multiple data sources. Optimized retrieval with reranking. Full application development with your required integrations.
Enterprise RAG Platform
Enterprise-wide deployment with security requirements
$75,000 – $150,000+
3-6 months
Multiple knowledge bases
Role-based access control
Agentic RAG capabilities
Enterprise SSO integration
On-premise deployment option
Custom security requirements
SLA-backed support
Dedicated success manager
Enterprise-scale RAG with multiple use cases, role-based access, advanced security, and organizational integrations. For companies deploying RAG across departments.
Ready to Build Your RAG System?
Start with a free discovery week. We'll analyze your documents, test retrieval feasibility, and provide realistic estimates—before you commit to anything.
Why Companies Choose RAG Over Traditional Approaches
RAG fundamentally changes what's possible with AI and your documents. Here's why it matters.
Answers grounded in facts, not hallucinations
The fundamental problem with LLMs: they make things up. RAG changes that. Every answer retrieved from your actual documents. Every claim backed by a source citation. Users can verify. Auditors can trace. When the system doesn't know, it says so instead of inventing an answer. This is what makes RAG enterprise-ready.
Knowledge that stays current without retraining
Fine-tuned models freeze knowledge at training time. New product launches, policy updates, recent research—none of it exists in the model. RAG stays current because it retrieves from your live knowledge base. Update a document and the system knows immediately. No retraining. No waiting. No $50,000 fine-tuning bill every quarter.
Production RAG experience, not demos
RAG demos are easy. Production RAG is hard. Edge cases that break chunking. Queries that require information from multiple documents. Users who phrase questions in unexpected ways. We've shipped RAG systems that handle real traffic, real complexity, real user expectations. Our AI support agent processes thousands of queries daily. We know what breaks and how to fix it.
Cost-efficient at scale
RAG can get expensive fast. Vector database costs. Embedding API calls. LLM tokens for generation. We architect for efficiency from day one. Intelligent caching. Tiered retrieval that tries cheap options first. Query routing that uses smaller models when they're sufficient. Our benchmark: $0.02 per conversation. That's not an accident—that's deliberate architecture.
Why Work With ProductCrafters
RAG development requires a specific combination of skills. Here's what sets us apart.
RAG in production, not just POCs
We've built RAG systems that serve real users at scale. Our AI support agent handles thousands of queries daily at $0.02 per conversation. Healify raised $2M with RAG-powered health knowledge retrieval. The gap between a working demo and a reliable production system is vast. We've crossed it repeatedly.
Full-stack, not just ML
RAG systems need more than good retrieval. They need APIs, frontends, authentication, monitoring, and integration with existing systems. We handle the entire stack—from vector database configuration to the chat interface users interact with. One team. One point of accountability.
Honest about what works
Sometimes RAG isn't the answer. Sometimes your documents aren't ready. Sometimes the accuracy requirements are unrealistic for the budget. We'll tell you. Our job is solving your problem, not selling you a RAG project. If a simpler approach works better, we'll recommend it.
Transparent pricing
No competitor on the first page of Google shows RAG development pricing. We do. RAG implementation starts at $25,000. Production systems run $35,000-$75,000. Enterprise deployments can exceed $100,000. You know what you're getting into before we start.
Recognition
Trusted by Industry Leaders
FaQ
What is RAG and how does it work?
RAG (Retrieval-Augmented Generation) is a technique that connects large language models to external knowledge bases. Instead of relying solely on training data, RAG systems retrieve relevant documents before generating responses. The process works in three steps: (1) your question gets converted to an embedding, (2) similar content is retrieved from a vector database, (3) the retrieved context is combined with your question and sent to an LLM for response generation. The result is answers grounded in your actual documents, with citations users can verify.
How much does RAG development cost?
RAG implementation costs vary by scope. A proof-of-concept with single data source runs $15,000-$25,000 over 4-6 weeks. Production RAG systems with multiple sources, advanced retrieval, and full application development cost $35,000-$75,000 over 8-12 weeks. Enterprise deployments with security requirements, multiple use cases, and organizational integrations can exceed $100,000. The main cost drivers are document complexity, accuracy requirements, and integration scope. We provide detailed estimates after a discovery phase that assesses your specific situation.
What is the difference between RAG and fine-tuning?
RAG retrieves external information at query time; fine-tuning changes the model's internal weights through training. RAG keeps knowledge current (update a document and the system knows immediately), provides citations, and handles large knowledge bases efficiently. Fine-tuning is better for learning patterns, styles, or domain language that's stable over time. Many production systems use both: a fine-tuned model that understands domain vocabulary, connected to RAG for current factual retrieval.
How long does it take to build a RAG system?
Timeline depends on complexity. Simple proof-of-concept: 4-6 weeks. Production system with integrations: 8-12 weeks. Enterprise deployment: 3-6 months. The first 1-2 weeks are discovery—analyzing documents, defining accuracy targets, designing architecture. Pipeline development takes 2-4 weeks. Application development adds 3-5 weeks. Integration and testing require 2-3 more weeks. We provide specific timelines after the discovery phase when we understand your requirements.
What are the types of RAG systems?
RAG architectures have evolved beyond basic retrieval. Naive RAG uses simple vector search with a single retrieval step. Advanced RAG adds query rewriting, reranking, and multi-step retrieval. Modular RAG allows customization of each pipeline component. Agentic RAG incorporates reasoning—the system decides what to retrieve based on the query. Graph RAG combines knowledge graphs with vector retrieval for relationship-aware answers. Hybrid RAG combines semantic search with keyword matching. The right type depends on your accuracy requirements and query complexity.
Is RAG better than fine-tuning?
Neither is universally better—they solve different problems. RAG is better when: your knowledge changes frequently, you need citations and traceability, your corpus is large, or factual accuracy is critical. Fine-tuning is better when: you need consistent style or voice, the task requires pattern learning rather than fact retrieval, or outputs need specific formatting. For many enterprise applications, RAG is the starting point because it provides verifiable answers with audit trails. Fine-tuning often complements RAG rather than replacing it.
How do you ensure RAG accuracy and reduce hallucinations?
Hallucination reduction is built into our RAG architecture. First, retrieval precision: we optimize chunking, embeddings, and reranking until the right documents are consistently retrieved. Second, generation guardrails: prompts instruct the model to answer only from retrieved content and admit uncertainty. Third, confidence scoring: low-confidence responses get flagged or filtered. Fourth, citation requirements: every claim must reference a source document. Fifth, human-in-the-loop: high-stakes applications include review workflows. Zero hallucination is impossible, but enterprise-acceptable rates are achievable.
Can RAG work with my existing data sources?
Yes. We integrate RAG with common enterprise data sources: SharePoint, Confluence, Google Drive, Notion, S3, databases, and custom systems via API. Document formats include PDF, Word, HTML, Markdown, and plain text. Complex formats (scanned documents, spreadsheets with formulas, presentations with graphics) require specialized extraction. During discovery, we assess your data sources and identify any that need special handling. Role-based access controls ensure users only retrieve content they're authorized to see.
Is RAG HIPAA/SOC 2 compliant?
RAG can be implemented with HIPAA, SOC 2, GDPR, and other compliance frameworks. Compliance depends on architecture choices: where data is stored, how it's transmitted, who can access it, and what audit trails exist. For HIPAA, this means encrypted storage, access logging, BAA with vendors, and careful handling of PHI. For SOC 2, it means security controls, monitoring, and documented procedures. We've built compliant RAG systems for healthcare and financial services. Compliance adds cost but is achievable when required.
What happens if my data changes frequently?
RAG handles dynamic knowledge well—it's one of the main advantages over fine-tuning. When documents update, you re-process them through the ingestion pipeline. This can be automated: file system watchers, scheduled syncs, or webhook triggers from your content management system. The vector database updates, and queries immediately reflect current information. For real-time requirements, we implement streaming ingestion. For most use cases, hourly or daily sync is sufficient. No model retraining required.
What is RAG as a Service?
RAG as a Service (RaaS) provides managed RAG capabilities via API, eliminating the need to build infrastructure from scratch. Providers handle document ingestion, vector storage, and retrieval orchestration. You connect your data sources and make API calls. Benefits: faster deployment, no infrastructure management. Trade-offs: less customization, potential vendor lock-in, data leaves your infrastructure. We build custom RAG when you need specific accuracy requirements, security controls, or capabilities that managed services don't provide.
Do you provide ongoing RAG maintenance and support?
Yes. RAG systems need ongoing attention. Retrieval accuracy drifts as content changes. New query patterns emerge that weren't anticipated. Costs need optimization as usage scales. Our maintenance includes: monitoring retrieval quality, updating pipelines for new document types, optimizing for cost efficiency, and adapting to evolving requirements. Most clients continue working with us after launch because the system needs to improve over time, not just maintain the status quo.
Start Your RAG Project Risk-Free
Risk-Free Start
Your Free Trial Sprint
1
Week 1
Meet your team
Slack channel, assigned developer, daily standups. First code committed to your GitHub.
2
Week 2
Working prototype delivered
Technical spike or prototype complete. Architecture + budget roadmap for the full build.
You keep everything. Zero cost. Zero commitment.
Oleg Kalyta
Founder & AI Lead
What happens next:
1.You submit—We review within 24 hours
2.15-minute scoping call—We align on trial goals
3.Developer assigned—Within 48 hours
4.Working code in your repo—By end of Week 1
What is RAG Development?
Retrieval-Augmented Generation (RAG) development is the process of building AI systems that combine large language models with external knowledge retrieval. Unlike traditional LLMs that generate responses solely from training data, RAG systems retrieve relevant information from your documents, databases, or knowledge bases before generating answers. This grounds AI responses in verified facts, provides source citations, and keeps knowledge current without expensive model retraining. RAG development involves designing retrieval pipelines, optimizing vector databases, configuring embedding models, and building applications that deliver accurate, source-backed answers to users.
Retrieval Pipeline Engineering
Building the infrastructure that converts documents into searchable embeddings, stores them in vector databases, and retrieves relevant content for each query.
Knowledge Base Integration
Connecting RAG systems to your actual data sources: documents, wikis, databases, and APIs. Keeping content synchronized as information changes.
Generation Optimization
Configuring LLMs to generate accurate responses from retrieved context, including citation handling, confidence scoring, and hallucination prevention.
Production Deployment
Taking RAG from prototype to production: monitoring, scaling, cost optimization, and maintaining accuracy as usage grows.
Enterprise RAG Development
Building for a large organization? Enterprise RAG has additional requirements.
Security and compliance
Enterprise data can't just flow to external APIs. On-premise deployment, private cloud setups, data encryption, audit logging. HIPAA, SOC 2, GDPR compliance when required. Your legal team signs off before we deploy.
Role-based access control
Different users should see different information. RAG systems that respect your permission model. Executives see strategic documents. Engineers see technical specs. Nobody sees what they shouldn't.
Multi-department deployment
RAG that scales across the organization. Shared infrastructure with department-specific knowledge bases. Central management with distributed ownership. Consistent experience, customized content.
Integration with enterprise systems
RAG connected to your SSO, integrated with SharePoint and Confluence, feeding answers into Slack and Teams. Fits into existing workflows instead of creating new silos.