


Artificial intelligence is having a massive impact, pouring trillions of dollars into the global economy each year. It’s used for everything from pricing and fraud prevention to supply chain optimization and customer engagement. The global spend on AI tools is rising fast, but most of that money is going into developing and deploying AI models rather than just experimenting with them.

As a result, the pressure is on to get these AI models right. If an AI model is poorly trained, evaluated or monitored, it can start to degrade and introduce operational risk. To succeed in the long term with AI tools, you really need to understand how to create models that work.
Table of Contents
Understanding Artificial Intelligence: How AI Systems Really Work
What Is Artificial Intelligence?
Artificial intelligence (AI) refers to systems and machines that can perform tasks that typically require human intelligence, such as solving complex problems, learning from past experiences, or making decisions when the outcome is uncertain.
Unlike traditional software, which simply follows instructions, AI takes a different approach: it analyses large amounts of raw data, finds and recognizes patterns, learns from them, and improves over time. By combining clever algorithms with powerful computing, AI can tackle complex problems, make informed predictions, and uncover insights that would be difficult for a human to discover on their own. The impact of this technology has been truly transformative.
The Role of AI Models
At the heart of any given AI system is an AI model. It is a piece of software that has been trained on data to figure out how things are connected, make some educated guesses, and then take some action. But on its own, an AI model is basically useless. In the real world, though, it needs to be part of a bigger system that includes a process for feeding it more data, evaluating how well it’s doing, and keeping an eye on how it performs in practice. Building such a system is by no means straightforward.
From Algorithms to Integrated Systems
These days, most AI systems are more than just one algorithm; they’re a whole pipeline of components, all working together to achieve a particular goal. Designing such a system takes a lot of care and attention to get the data quality right, set up the right feedback loops, and the overall architecture. Each part has to be put together in the right order so the system can learn properly, make odd, accurate predictions, and adapt to changes as they come in, so that AI delivers real results in the real world.
Defining the Problem: The Foundation of AI Success
Every AI system starts with a well-defined problem to solve. And that means defining what decision the AI model is meant to support or automate, and under what conditions it’s supposed to be working. If the problem definition is vague or too broad, the whole thing is likely to fail.
A well-defined problem is one that turns a business or operational goal into a clear task that can be measured and evaluated. That includes figuring out what the output is meant to be, how much room there is for error, and how long it’s meant to take. For example, predicting customer churn or detecting fraud are both AI tasks that need to be approached in very different ways.
And that problem definition is going to shape just about every decision you make along the way, from what data to collect and how to engineer the features of that data to which algorithm to use and how to evaluate its performance. If you don’t get the problem definition right, even a well-trained model is likely to end up optimizing the wrong thing, which means it will fail in the real world, even if it looks good in testing.


The Appropriate Algorithm for the Job
Once your data is in a state that’s usable, the choice of algorithm becomes a real constraint on everything else: training time, model performance, how explainable it is, and even operational cost. This isn’t so much about picking the “best” AI model as it is about finding one that fits the problem you’re trying to solve and the data you’re actually working with.
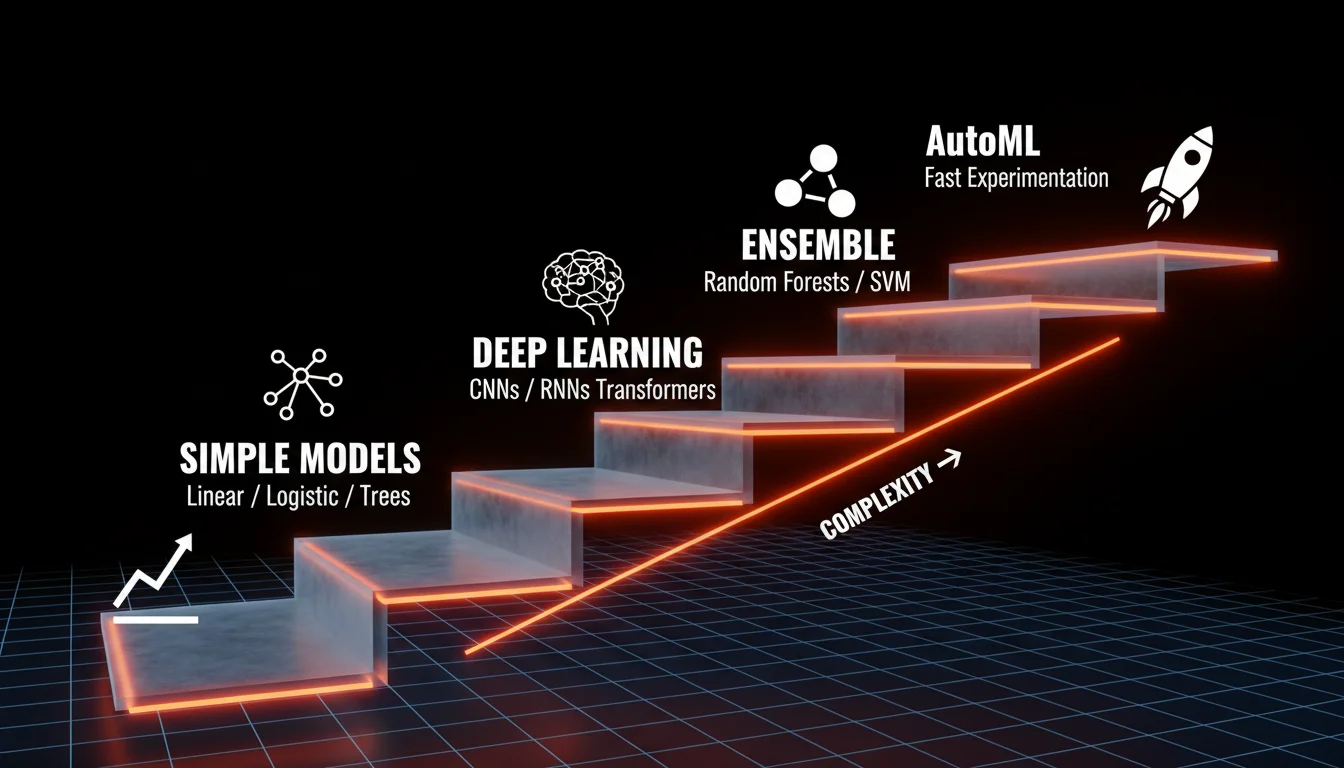
When Simple Models Do Just Fine
If your data is structured and the relationships are clear-cut, then starting with something simple is usually the way to go.
- Linear Regression is great for when you’re looking at a continuous output\
- Logistic Regression is a good choice when you need to classify something as either yes or no\
- Decision Trees are good when you need to apply a set of rules to make a decision.
These models are based on old-school statistical analysis; they’re fast to train, easy to debug, and they’re a lot easier to explain to non-tech folks. In reality, they’re still being used for a lot of the heavy lifting in production systems. You can find them powering systems that do things like spam detection, basic fraud screening and customer behavior analysis.
More Complex Relationships
As soon as your data starts to be less predictable: you’re looking at non-linear patterns, multiple interacting input features or noisy signals, and your simple models start to break down.
- Random Forests and other ensemble methods can handle it a bit better.
- Support Vector Machines (SVMs) can handle high-dimensional feature spaces like a pro.
These models can pick up on more complex patterns, but there’s a trade-off: training takes longer, getting the right settings is much more important and small datasets can become a real bottleneck.
Images, Text and Sequences
For unstructured or sequential data, classical machine learning really isn’t up to the task.
- Convolutional Neural Networks (CNNs) are perfect for image and visual data.
- Recurrent Neural Networks (RNNs) and transformer-based models are what you use for text, speech and time series; these architectures can learn feature representations on their own, which is their main perk. The downside is that you need a lot more computing power, longer training cycles, and there is a greater risk of overfitting if your dataset isn’t big enough.
AutoML’s Place in All This
AutoML tools sit on top of all these approaches.
- They automate the process of comparing different algorithms.
- They handle hyperparameter tuning for you.
- They speed up the experimentation process at the start.
They don’t replace understanding the problem or the data you’re working with at all. But they do cut down on all the repetitive trial and error that you might otherwise be doing. Used correctly, they help teams move a lot faster without locking themselves into some potentially dodgy early decisions.
Choosing the right algorithm isn’t about finding a model that’s as complicated as possible. It’s about finding the simplest approach that meets your needs and knowing when that approach stops being enough.
| Data Type | Typical Use Case | Recommended Models |
|---|---|---|
| Tabular data | Classification, prediction | Linear / logistic regression, decision trees |
| Tabular data | Complex patterns, risk scoring | Random forests, SVMs |
| Text & sequences | NLP, speech, time series | RNNs, transformer-based models |
| Images & video | Image recognition | Convolutional neural networks |
| Large datasets | High-accuracy modeling | Deep neural networks |
| Any | Fast experimentation | Pretrained models, AutoML tools |
Ultimately, the right algorithm is the one that balances performance, interpretability, training cost, and deployment constraints within the broader AI system.
Approaches to AI Model Selection
Picking an AI model is a decision that sounds straightforward, but quickly becomes a real-world headache. In theory, it’s all about finding the “perfect” algorithm – but in reality, it is about finding one that works with the data you’ve got, the problem you’re trying to solve, and the constraints you’ll need to live with in a few months’ time.
Data shape and volume are a big deal. And so are things like being able to explain why a model made a certain decision. And let’s not forget compute costs sneaking up on you, or how much of a pain maintenance is going to be once you’ve deployed the model. All of these things start shaping the choice well before anyone even discusses model performance.
The Three Learning Paradigms You’ll Actually Encounter
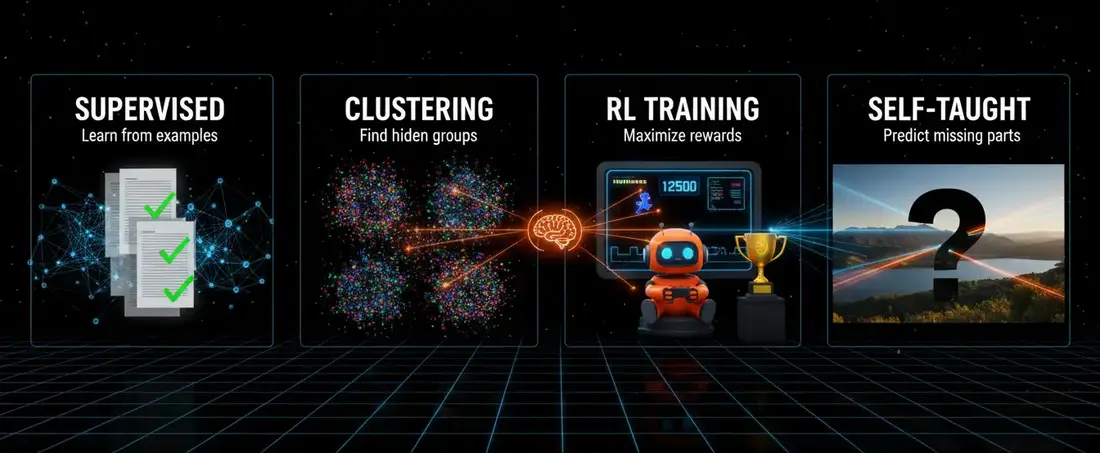
Most specialized model decisions fall into one of a few broad categories.
Supervised Learning
Supervised learning is where most production systems start: you’ve got labelled data, you know what works, and you can track progress. Fraud detection, spam email filtering, credit scoring, and forecasting are all pretty familiar territory. You can iterate quickly, debug stuff, and defend your results with a bit more confidence.
Unsupervised Learning
Unsupervised learning is used when your labels are missing or unreliable. It’s useful for finding patterns in data rather than predicting specific outcomes. You might use it to segment customers, detect unusual behavior in logs, or uncover unexpected patterns in transactions. At this stage, you’re exploring the data and deciding what actually matters. When training models for unsupervised learning, factors like learning rates play an important role in how quickly and effectively the model converges on meaningful patterns.
Reinforcement Learning
Reinforcement learning is a whole different ball game. It’s about making decisions in real time, feedback loops, and delayed outcomes. Think about pricing strategies, adapting recommendations or control systems. It’s powerful, but don’t be in a rush to reach for it.
The reality is that teams stick with supervised learning for as long as they can. It’s not the most exciting stuff, but it’s predictable, and predictability is worth a lot to people.

Start Small. Earn Complexity.
Lots of AI projects go wrong because they start with too much complexity too early on. When your data is clean and your features make sense, a simple model can go a long way.
- Linear and logistic regression still show up in serious financial systems, like credit risk, default probability or compliance-heavy environments. Not because they’re old, but because they’re just easy to understand.
- Decision trees are standard in a lot of operational workflows, like eligibility checks, approvals or rule-driven decisions. People like what they can see and trace.
- Tree-based ensembles like random forests or gradient boosting come in when linear models stop working for you. Stuff like fraud detection, predicting customer churn or Behavior modeling. You get more accuracy without everyone losing their mind trying to understand how the model is making decisions.
These models are fast to train, cost less to run and are easier to support in production. And the bonus is they tend to fail in a more predictable way.
Only turn to super-complex architecture when the simpler methods really are biting you – not just because you think they’re intellectually cool.
Machine Learning vs. Deep Learning Models

The choice between classical machine learning and deep learning ultimately comes down to how complex and unorganized your data is.
Classical machine learning really shines with tabular data that’s laid out in neat rows and columns, which is exactly what you’ll find in most business systems:
- In e-commerce, people often use models based on decision trees or gradient boosting to try and get a handle on customer behavior, optimize prices or forecast demand.
- In finance, tabular models are still the option for risk modeling because they’re easy to understand and super reliable.
Deep learning, on the other hand, is perfect for dealing with loads of unstructured data like images, audio or video:
- Convolutional neural networks (CNNs) are used in healthcare for X-rays and MRI scans, for example, and can be used to spot anomalies that might have otherwise gone unnoticed.
- Recurrent neural networks (RNNs) and transformer-based models underpin applications like speech recognition, document classification and time-series forecasting in logistics and monitoring systems.
Now, while deep learning models can often produce stunning results in these areas, they need a lot of data, expensive hardware and careful tweaking to get the most out of them. For many use cases, it’s just not worth the extra hassle when simpler basic models can do the job just fine.
So here’s a simple rule of thumb: your choice depends on the type of data you’re working with. If it can all fit neatly into rows and columns, classical machine learning is usually the way to start. But if you’re dealing with images, text, audio, or video, deep learning is likely your best option.
Neural Networks and Model Architecture
Neural networks are made up of an input layer, a bunch of hidden layers, and an output layer. Each layer works its magic on the data coming in by applying weighted connections and activation functions, which let the model learn to spot more and more complex patterns.
But how you design your neural network is going to have a big impact on how well your model performs, and how easy it is to work with:
- The deeper your network is, the more powerful it’ll be, but it’s also going to be a lot more likely to go off the rails and overfit to the training data.
- The bigger your network is, the more data you’ll need, the longer your training sessions will take, and the more expensive it’ll be to deploy model and run it.
- Get your design wrong, and you could end up with a network that won’t train properly or takes ages to converge.
In practice, teams rarely start from scratch when it comes to designing neural networks. Instead, they tend to rely on proven architectures or pre-trained models, especially when they’re short on data. Because fine-tuning an existing model is usually faster, safer and a lot more cost-effective than building a whole new one from scratch.
When it comes to making a good AI model, it’s all about finding the right balance between performance and all the other things that matter: scalability, interpretability, and just plain old practicality.
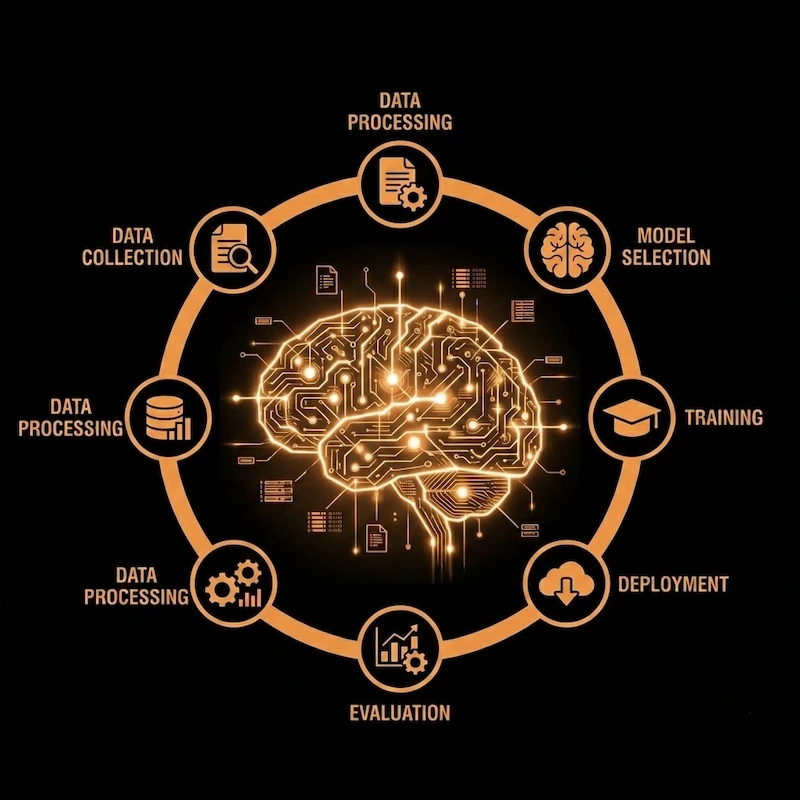
Step-by-Step Guide to Building an AI Model
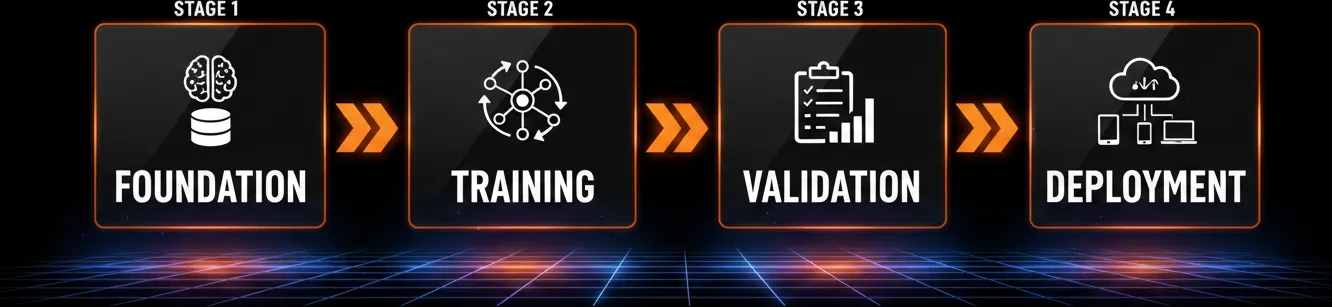
The infographic you see above gives us a bird’s-eye view of an entire AI model lifecycle from start to finish, from figuring out what needs to be done, gathering data, putting things into place, and continuously making them better.
Phases 1-2: Getting Off the Ground
The journey starts by nailing down the problem you’re trying to solve, what data you need to work with, what you want as output & just what will be considered a success. You then go out and collect and clean up some decent data to work with. This is the foundation on which your model is going to be built and will directly impact how well it does when training process starts. Make no mistake, clean, well-structured data & meaningful features are the difference between a good model and a great one.
Phases 3-5: Choosing the Right Tool and Conducting AI Training
Once you’ve got your data in order, it’s time to pick an algorithm that’s suitable for the task at hand, taking into account things like how big the data is, any operational restrictions and the type of task. While the model is training, it’s constantly generating predictions, checking to see how wrong it is & updating itself with new information – pretty much the core loop of how an AI system learns.
Phases 6-7: Putting it Through Its Paces and Dialling It In
Assuming your model is doing okay with your training data, it’s now time to put it to the test and see just how it stacks up against other data metrics like accuracy, precision and recall, which are used for classification tasks, while regression tasks will use things like mean squared error and R-squared to measure performance.
When trying to see how well it does in real-world situations, cross-validation comes in handy – repeated runs to see if it’s going to do okay elsewhere. And of course, in an effort to stop it from getting too reliant on its training data, you’ll be using techniques such as regularization, dropout and early stopping to keep things in check.
Phase 8: Putting it Into the Wild
Once validation has confirmed it’s going to do just fine in the real world, you can finally deploy it to a business, which may be on a cloud platform for scalability, on your own hardware for security or even on a device to enable those all-important low-latency reads. APIs and tools like containerization mean you can get your model into the right place and make use of it, as shown by the final stage of the infographic.
Beyond the Infographic: Where The Real Work Starts
Deployment does not mark the end of work. Real conditions and the data your model relies on are constantly changing. In addition to establishing a repeatable workflow, continuous monitoring of the AI model and tracking evaluation metrics are crucial to ensure it remains accurate and effective over time.
Security, Privacy, and Ethical AI Development
Responsible AI development actually goes beyond just having a model that works well. It involves putting in some deliberate effort to think about security, privacy, fairness, and accountability right from the start, and keeping these ethical concerns in mind throughout the process of building and deploying an AI system.
Protecting Data
When it comes to handling sensitive information in AI pipelines, you need to have some straightforward security measures in place. Things like strong encryption when the data is sitting around and when it’s in transit, and also strict controls on who has access to it. Whenever possible, it’s a good idea to do as much processing as possible right on the device or in a secure local environment so you don’t have to expose that sensitive data unnecessarily. These precautions can really help limit the risks, even if some part of the system does get compromised.
Regulatory Requirements
There are also specific regulatory frameworks that come into play depending on the type of data you’re dealing with: things like GDPR and HIPAA impose clear rules around how you need to collect, store and process personal and medical data.
AI systems need to be designed to support things like only collecting what you need, being able to audit what’s happening, and giving people the right to see the information you’re using to make decisions. If you don’t comply with these rules, it is not just financial penalties you have to worry about, but also reputational damage and loss of public trust.
Bias in AI
Ethical risks don’t stop at data security. Bias is a persistent issue, especially when training data reflects historical or structural inequalities. Left unchecked, models can quietly reinforce those patterns at scale.
Detecting and Mitigating Bias
Detecting and addressing biases in AI models is an ongoing process. You can’t rely on a one-off check and hope for the best. Using tools like dataset audits, bias metrics, and explainability methods such as SHAP and LIME helps teams understand how models are making decisions. These practices are essential for identifying and addressing biases, especially in high-stakes domains like healthcare, finance, and fraud detection, where fairness, transparency, and accountability are critical.
Human Impact of AI
And let’s not forget about the broader impact of AI on society. As AI model starts to automate more and more tasks across industries, job loss becomes a growing concern. But more and more organizations are now focusing on augmenting human capabilities rather than replacing them, so that people are still in control of the important decisions and AI systems are just there to help out with the repetitive or data-intensive stuff.
Common Pitfalls in Building AI Models
Loads of AI projects fail not because of the technology, but due to some really avoidable mistakes that people make when they’re creating their own AI models.

Data and Model Challenges
One of the most common issues is poor data quality, which can limit the accuracy and usefulness of predictions, no matter how sophisticated the AI model is. If the labels are inconsistent, data is missing, or the samples aren’t representative, it can significantly weaken the machine learning process and reduce the reliability of the results.
Another common mistake is introducing overly complex models too early in the process. Pursuing very deep architectures or extremely large models increases costs, slows down experimentation, and makes debugging much harder. In many cases, this level of model complexity does not even deliver better results than simpler approaches.
Operational and Deployment Issues
Operational inefficiencies can also trip teams up. Slow training pipelines, unoptimized data processing, or inadequate hardware can stall the creation of AI model progress and drive up costs. Equally important is monitoring models after deployment; ignoring this can allow model drift, bias, and performance degradation to go unnoticed.
But if you want to have any chance of success with AI model development, you need to make sure you define the problem clearly, get your data collection in order, validate your approach, establish relevant performance metrics to measure how well your model is doing, and make sure you have everything up and running properly.
Future Trends In AI Development
Rapid Market Growth
The pace of AI development is picking up rapidly across a variety of areas. Breakthroughs in models, infrastructure and deployment methods are all helping to speed things up. And the stats are pretty astonishing. The global AI market is expected to grow to nearly two trillion dollars by 2030, roughly twenty times the current size. That’s how widespread the adoption of AI is expected to be across all sorts of industries.
Multimodal and Autonomous AI
Now we’re starting to see AI models that can handle multiple mediums at once: text, images, audio & video all seamlessly interacting with one another. Around the same time, quite sophisticated autonomous AI systems are emerging. These are platforms designed to get things done, able to plan, execute & interact with tools with minimal human input needed.
Edge AI and Real-Time Intelligence
Taking AI to the edge means we can put intelligence right where data is generated. This reduces latency and privacy concerns since less data needs to be sent to central servers. It’s really useful for healthcare devices, industrial equipment and real-time analytics.
Open-Source AI and Accessibility
Open source initiatives are making AI more accessible and transparent, and that in turn is allowing companies to customize systems to their specific needs; no longer are they reliant on expensive proprietary platforms.
Responsible and Sustainable AI
As these trends converge, it’s clear that building successful AI projects requires more than just technical know-how. It also needs responsible AI design and governance and a long-term commitment to maintainability right across the entire lifecycle of the AI system.
Conclusion: Building AI Models That Work in the Real World
Building an AI model isn’t just a single technical breakthrough; it’s a whole sequence of well-coordinated decisions about the data, the algorithms, the infrastructure and the operations. Models succeed when the problem’s been clearly defined, the data’s been prepared properly, and you’re using algorithms that reflect how things really work in the real world.
As AI systems move from experimentation into production, long-term reliability becomes at least as important as raw performance. Continuous evaluation, responsible data handling and disciplined MLOps practices can turn individual models into dependable AI systems that keep up with the business as it evolves.
Teams that treat AI model development as an ongoing engineering discipline (grounded in fundamentals, transparency and iteration) are best placed to deliver rich ecosystems that stay accurate, scalable and valuable over time.







